This is a personal blog. All opinions are my own - not my employer’s.
At some point over the last few months, I accidentally built a control plane for coding agents.
This was not the plan.
The plan, to the extent that there was one, was much smaller and much more normal. I wanted coding agents to stop behaving like enthusiastic chaos goblins with write access to a repository. I wanted smaller pull requests, cleaner context, better validation, fewer mysterious refactors, and a lower chance of discovering that an AI assistant had interpreted “add JSON output” as “please introduce an entire new architectural religion”.
Reasonable things.
Then GitHub changed the billing model, AI Credits arrived, CopeLimit started watching the meter, and the whole thing became much more invoice-shaped.
That was the first turn in the road. I had already written about the practical workflow in Sculpting with Agents: From Prompting to the Agile Agentic Development Life Cycle (AADLC). I then wrote about the economics in FinOps for Delegated Cognition: AADLCv2 and the Cost of Letting Agents Rediscover Gravity, followed by the billing weirdness of the first morning of GitHub’s AI Credits model and the more pointed observation that GitHub boiled the frog backwards.
Those posts were not wrong. Helpful start. Good little trail of breadcrumbs. Mildly cursed breakfast cereal for anyone trying to understand why my hobby projects suddenly contained more accounting language than some finance systems.
But they were incomplete.
Because the thing that has become clearer since then is that AADLC was not just a workflow. It was the early shape of a control loop .
The problem was never just prompting.
Prompting helps. Good prompts matter. Clear intent matters. Boundary-setting matters. Anyone who says prompts do not matter has probably not watched a coding agent confidently wander into the shrubbery because a human gave it a vague sentence and a dream. But prompting is not a control plane. A prompt is an instruction thrown into a probabilistic system. A control plane is what gives that system durable state, authority boundaries, policy, feedback, validation, and a way to learn without turning every new session into a fresh attempt to rediscover gravity.
That distinction is where AADLC has been heading all along.
The thesis was not that agents are bad
The original AADLC thesis was never “AI coding agents are bad”. That would be boring, and also obviously untrue.
They are useful. They are sometimes astonishingly useful. They can turn half-formed ideas into working scaffolds, write tests I would have postponed, spot boring inconsistencies, and chew through implementation detail while I stay at the altitude where the actual design decisions live.
The problem is that useful is not the same as governed.
A fast agent without boundaries is not an engineer. It is a distributed ambiguity amplifier with a cheerful tone and a shocking tolerance for touching files you did not ask it to touch.
That sounds harsh, but it is also the behaviour I kept seeing. Not because the models were stupid. Often the opposite. The better models were sometimes more dangerous, because they were better at finding the larger abstraction hiding behind a small request.
Ask for a small CLI improvement and the pragmatic model might add the flag, update the tests, document the behaviour, and stop. Lovely.
Ask a more architecturally hungry model the same thing and it may decide the real problem is that the repository lacks a generalised output subsystem, shared format dispatch, broader validation semantics, extra command coverage, new documentation structure, and possibly a small shrine to extensibility near the package manager.
None of that is necessarily wrong. That is the awkward bit.
The agent may be making a defensible engineering choice. It may even be making the better long-term choice. But if the task contract was small, the trust boundary was narrow, the budget was finite, and the human expected a reviewable diff, “technically defensible” is not enough. Architecture has a blast radius. In agentic systems, it also has a credit footprint.
That was one of the first things the benchmark runs made visible. The interesting question was not “which model is best?” It was “what shape of delegation does this work need?”
That sounds like a small wording change. It is not.
It moves the conversation away from leaderboard thinking and toward systems thinking. The model matters, obviously. But the model is only one part of the operating system. The task shape, durable memory, current contract, validation path, correction budget, and cost telemetry all change the result.
In other words, the agent is not the system.
The delegation system is the system .
What AADLC actually got right
AADLC started as the Agile Agentic Development Life Cycle. The name is a bit of a mouthful, which is tradition for anything that starts as a useful engineering practice and eventually threatens to become a diagram.
The useful part was the loop:
- Shape the work before execution.
- Plan explicitly.
- Execute only the approved scope.
- Validate deterministically.
- Reset context into durable memory before moving on.
That sounds obvious when written down. Most useful controls do. Seatbelts are also not conceptually difficult, and yet somehow humans still needed a few decades and legislation to stop treating windscreen roulette as a personal philosophy.
The AADLC loop worked because it attacked the failure modes I kept seeing rather than trying to make the model “smarter”. It did not assume the agent would naturally infer the right boundary. It made the boundary explicit. It did not trust fluent confidence as evidence of correctness. It required validation. It did not let every chat session become a diary of temporary compromises. It separated durable project truth from ephemeral working context.
The most important part was semantic hydration.
Every coding agent has to hydrate itself into a repository. It has to learn the stack, layout, conventions, test commands, trust boundaries, dependency patterns, and the local definition of “do not be clever here”. If that knowledge lives only in a human’s head, every session pays for rediscovery. If it lives only in chat, it decays. If it lives only in documentation written for humans, the agent may skim it, misread it, or ignore the parts that matter.
So AADLC said: put the important operational truth in version-controlled files. Make it agent-readable. Make it diffable. Make it part of the repository.
That was the first piece of the control plane.
Then cARL happened
cARL is the thing AADLC turned into when the workflow stopped being a private operating habit and started needing a durable shape.
The acronym is intentionally ridiculous, because apparently I name things like a person who should not be left unsupervised near capital letters. It stands for Cognitive Agent Runtime Layer.
Underneath the name, the idea is straightforward: cARL is a version-controlled governance and instruction layer that lives inside a repository and shapes how AI coding agents behave every session, every task, without re-prompting the same rules into the void.
AADLC is the methodology. cARL is the repository-native control surface.
That distinction matters.
AADLC says: shape, plan, execute within bounds, validate, reset.
cARL says: here is where those truths live, here is how they are loaded, here is how they are projected into the agent harness, and here is how we stop them drifting.
A cARL-managed repository has durable artefacts such as:
.github/carl/memory.md
.github/carl/current-pr-contract.md
.github/carl/invariants.yml
.github/carl/trust-boundaries.md
.github/carl/tool-policy.yml
.github/carl/plans/
.github/instructions/core/
.github/instructions/languages/
.github/instructions/platform/
.github/instructions/cloud/
The exact filenames will evolve, because software is how humans discover which names were optimistic. But the structure is the point. The agent gets durable memory, active task scope, invariants, trust boundaries, tool-permission guidance, and focused instruction packs.
That last bit is important. cARL is not one giant prompt. Giant prompts are where clarity goes to wear a novelty hat and fall down stairs. cARL is modular. Core instructions set the baseline behaviour. Security instructions shape threat-aware review. Dependency instructions constrain package changes. Identity instructions matter for authn/authz-heavy work. CI/CD instructions guide pipeline changes. Language packs add TypeScript, Python, Terraform, PowerShell, JavaScript, HTML, and whatever else the repo needs. Cloud packs handle Azure, Entra, Microsoft Graph, GCP, Netlify, and similar domain-specific edges.
The effect is different from “please behave”. It is closer to giving the agent a job description, a map, an escalation policy, and a list of things it is not allowed to pretend are fine.
That sounds mundane. Good. Governance should often be mundane. The exciting version of governance is usually just an incident report in cosplay.
cARL is not ADRs, and it is not prompt engineering
This is one of the places where the terminology can get slippery, so it is worth being explicit.
Architecture Decision Records are written for humans. They are valuable. I like ADRs. ADRs record why a decision was made, usually after enough pain has occurred that someone realises future humans might benefit from not repeating the debate.
cARL is different. cARL is written for coding agents. It is loaded before the task. It turns durable decisions into operating constraints. Where an ADR says “we chose this”, cARL says “because this was chosen, do not casually violate it during implementation”.
Prompt engineering is also different. Prompting is per-task. You write the prompt, run the session, and then the instruction disappears unless someone manually preserves it.
cARL is persistent. It is committed. It is diffable. It has git history. It survives session resets, model changes, team turnover, and the deeply human belief that we will obviously remember why the weird edge case mattered three months from now. We will not. Future us is not that trustworthy.
This is why I keep coming back to the same line:
AADLC was the discipline. cARL is the scaffold that stops the discipline from depending on me being in the room.
That is the part that feels real now.
The benchmark: same repo, different delegation shapes
The benchmark runs were my attempt to stop hand-waving and measure behaviour under comparable conditions.
The seed repository was deliberately modest. This was not an attempt to prove that one model could rewrite Kubernetes while playing the bagpipes. The benchmark asked coding agents to work through a controlled seven-phase AADLC sequence against the same seed commit and the same class of tasks.
The phases were:
| Phase | Purpose |
|---|---|
| 00 Hydration | Create/update AADLC artefacts only; understand the repo before touching application code. |
| 01 CLI feature | Add `–format text |
| 02 Validation bug | Handle invalid format values safely and deterministically. |
| 03 Tests | Strengthen automated CLI test coverage. |
| 04 Refactor | Improve maintainability of output formatting logic without changing behaviour. |
| 05 Docs | Update documentation and relevant governance artefacts. |
| 06 Review-hardening | Review all prior work against contract, memory, invariants, trust boundaries, and acceptance criteria. |
The measured runs were:
| Run | Credits | Time | Steering | Accepted phases |
|---|---|---|---|---|
| Claude Sonnet 4.6 only | 441 | 34m58s | 0 | 7/7 |
| GPT-5.4 only | 708 | 58m48s | 0 | 7/7 |
| Sonnet 4.6 plan + GPT-5.4 execute | 581 | 48m18s | 0 | 7/7 |
There was also a MAI-Code-1-Flash benchmark template in the set, but I am not counting it in the comparison because the run ledger was not populated. The annoying little discipline goblin who lives in my head insists that incomplete evidence is not evidence. Rude, but correct.
If you want to go into more detail than my summary which follows:
| Field | Value |
|---|---|
| Repository | https://github.com/goldjg/aadlc-gpt-5-4 |
| Model | GPT-5.4 |
| Model mode | |
| Run date | 03-06-26 |
| Operator | Graham Gold |
| Seed commit | https://github.com/goldjg/aadlc-seed/commit/7c35caa2c09d4c2e4e88180bf9dff013dcc1c0dc |
| Measured branch | benchmark/run-gpt-5-4 |
| Copilot/Coding agent surface | Web UI |
| Additional notes | |
| Benchmark Results | https://github.com/goldjg/aadlc-seed/blob/69d5f6042bdba4dd35d5986b5ad3a00cfb982338/benchmark/results/BENCHMARK_RUN_GPT_5.4.md |
| Field | Value |
|---|---|
| Repository | https://github.com/goldjg/aadlc-seed-sonnet-4-6 |
| Model | Claude Sonnet 4.6 |
| Model mode | |
| Run date | 03-06-26 |
| Operator | Graham Gold |
| Seed commit | https://github.com/goldjg/aadlc-seed/commit/7c35caa2c09d4c2e4e88180bf9dff013dcc1c0dc |
| Measured branch | benchmark/run-sonnet-4-6 |
| Copilot/Coding agent surface | Web UI |
| Additional notes | First-pass evaluation only. No human steering applied during measured phases. |
| Benchmark Results | https://github.com/goldjg/aadlc-seed/blob/69d5f6042bdba4dd35d5986b5ad3a00cfb982338/benchmark/results/BENCHMARK_RUN_SONNET_4.6.md |
| Field | Value |
|---|---|
| Repository | https://github.com/goldjg/aadlc-seed-sonnet-plan-gpt-5-4-exec |
| Planner model | Claude Sonnet 4.6 |
| Planner mode | |
| Executor model | GPT-5.4 |
| Executor mode | |
| Run date | 2026-04-05 |
| Operator | Graham Gold |
| Seed commit | https://github.com/goldjg/aadlc-seed/commit/7c35caa2c09d4c2e4e88180bf9dff013dcc1c0dc |
| Measured branch | benchmark/run-sonnet-plan-gpt-5-4-exec |
| Copilot/Coding agent surface | Web UI |
| Workflow | Sonnet planning, GPT-5.4 execution |
| Additional notes | |
| Benchmark Results | https://github.com/goldjg/aadlc-seed/blob/69d5f6042bdba4dd35d5986b5ad3a00cfb982338/benchmark/results/BENCHMARK_RUN_SONNET_GPT_5.4.md |
The headline is tempting: Sonnet was cheapest, GPT was most expensive, planner/executor sat in the middle.
That headline is also too shallow.
The more interesting finding is that the models behaved like different engineering roles.
Sonnet 4.6 behaved like a pragmatic senior engineer. It delivered accepted work quickly, stayed close to the ticket, kept the implementation narrower, and generally did not try to turn every task into a framework. For Phase 01, it added --format text|json to the info command. For Phase 03, it expanded test coverage from 10 to 33 tests across four suites. For Phase 04, it extracted info output formatting into a focused formatter module. It finished the full benchmark with zero human steering and the best cost-to-accepted-work ratio.
GPT-5.4 behaved like an architect holding the keyboard. It also completed all phases with zero steering, and it produced a broader, more globally coherent implementation. But it interpreted the output-formatting work as a global CLI capability rather than an info-specific feature. It added shared output support, updated multiple commands, hardened validation across a wider surface, added broader tests, and performed repeated validation and polish loops. That was valuable work, but it cost 708 credits and 58m48s. Compared with Sonnet 4.6, that was roughly 61% more credits and 68% more elapsed time for the same 7/7 accepted benchmark outcome.
The hybrid run was the most interesting. Sonnet planned. GPT executed. Sonnet produced dedicated plan files for each execution phase, and GPT-5.4 followed those plans without material scope drift. In the early implementation-heavy phases, this changed GPT’s behaviour dramatically. Instead of expanding the task into global CLI output architecture, GPT stayed scoped to the info command. Phase 01 changed only src/commands/info.ts and src/commands/info.test.ts. Phase 02 changed the same narrow area and added the invalid-format guard. Phase 03 remained test-only. Phase 04 produced a focused formatter extraction without touching unrelated commands or configuration.
That is the real result.
Sonnet planning did not make the workflow universally cheaper. The hybrid run still cost 140 credits more than Sonnet alone. Planning has overhead. Of course it does. Thinking before doing is not free, despite what some project plans appear to believe.
But Sonnet planning did make GPT-5.4 substantially cheaper and more controlled than GPT-5.4 alone. The hybrid used 127 fewer credits than GPT-only and avoided the architectural expansion that had driven downstream implementation, validation, documentation, and review cost.
That gives me the phrase I keep coming back to:
Ambiguity tax.
Ambiguity tax is the extra cost paid when an agent has to infer scope, architecture, risk tolerance, and success criteria instead of receiving them as explicit constraints.
Sometimes ambiguity tax is paid as money. Sometimes it is paid as time. Sometimes it is paid as review effort. Sometimes it is paid six weeks later when someone discovers that the helpful abstraction quietly changed the threat model. The invoice does not always arrive through billing telemetry. Sometimes it arrives wearing a pager.
The benchmark did not prove that one model is universally better. It proved something more useful: different delegation shapes produce different engineering behaviour. For small, well-bounded work, Sonnet alone looked best. For architectural review, defensive engineering, and broader validation, GPT-5.4 had clear value at a premium. For ambiguous or trust-boundary-sensitive work, planner/executor orchestration reduced GPT’s scope expansion and made its execution more predictable.
That is not leaderboard content. That is operating guidance.
The bit that surprised me: cARL works outside feature delivery
The early AADLC/cARL work was mostly about implementation tasks. Add this feature. Fix this validation bug. Add tests. Refactor this bit. Update docs. Review hardening.
Useful, but still comfortably inside “coding agent helps with code”.
Then I started using the same principles in messier review scenarios.
Not by installing some magical enterprise agent. Not by giving the model unlimited access and hoping it developed professional ethics on the fly. The pattern was much simpler: point the agent at the public cARL repository, tell it to hydrate the principles and instruction packs, and then use those principles as the review frame for another problem.
That sounds almost too simple, but it changed the quality of the output.
One exercise used cARL principles to review a pull request without relying on application-specific tribal memory. The useful part was not that the agent found “issues” in the generic sense. Finding issues is easy. A sufficiently motivated toaster could probably complain about a pull request if you gave it enough YAML. The useful part was that the review was structured around cARL-shaped questions:
- What does the PR contract imply?
- Which trust boundaries does the change cross?
- Are there new dependencies, permissions, network paths, or execution contexts?
- Are the validation claims backed by tests or just fluent confidence?
- Did the change update durable memory or invariants where the behaviour changed?
- Is the diff doing only what the task says, or smuggling in unrelated architecture?
That is a different kind of review from “summarise this diff”. It is closer to a governance review. It asks whether the change respects the repository’s operating model, not just whether the code compiles.
The same framing also worked when applied to a security pipeline. Again, not as magic. As structure. CI/CD work is full of dangerous assumptions because the code often looks boring. A pipeline change may be “just YAML”, which is one of the funniest lies we tell ourselves in modern engineering. YAML is where trust boundaries go to pretend they are whitespace.
Using cARL-style review, the pipeline analysis became less about whether the syntax looked plausible and more about whether the pipeline had clear trust boundaries, least-privilege permissions, deterministic validation, safe handling of secrets, sensible failure behaviour, and enough evidence that the checks being reported actually meant what humans thought they meant.
The same pattern worked again for application security gap analysis. The cARL security, dependency, identity, and platform instruction packs gave the review a shape: authn/authz boundaries, input handling, dependency exposure, logging and secret leakage, deployment assumptions, test coverage, CI enforcement, and places where the application relied on convention rather than control.
That was a bigger deal than I expected.
Because it suggested cARL was not only useful as an in-repo instruction set for the agent doing the implementation. It could also act as an external review lens. A repository could carry its own cARL runtime, but the public cARL repo could also be used as a reusable governance reference for reviewing systems that do not yet have cARL installed.
That is where the idea started to bend toward CI.
cARLy Gates: when cARL stops being advice and starts being a check
If cARL principles can guide review, the next obvious question is uncomfortable:
Why is this only happening in chat?
Chat is useful for exploration. It is not where controls should go to live. If an agent can review a PR against cARL principles, then some part of that review should eventually become repeatable, automatable, and visible in CI.
Enter the idea I am currently calling cARLy Gates, because apparently I am incapable of naming things without making future-me explain them in meetings.
The rough idea is a CI check for pull requests that evaluates whether a change respects the repository’s cARL governance contract. Not a replacement for tests. Not a replacement for code review. Not a magical AI bouncer at the nightclub of software quality, standing there in sunglasses saying “not in those shoes”.
A cARLy Gate would be more like a governance pre-flight check.
It could ask things such as:
- Does the PR have a current contract?
- Does the diff match the approved scope?
- Did the PR touch files that cross declared trust boundaries?
- Did it update
memory.md,invariants.yml, ortrust-boundaries.mdwhen durable behaviour changed? - Did it add dependencies without updating dependency rationale?
- Did it touch CI/CD without satisfying pipeline-specific instructions?
- Did it change authentication, authorisation, identity, secrets, or network boundaries?
- Did it update generated harness projection files directly instead of the canonical cARL source?
- Did it include validation evidence, or only claim validation happened?
- Did an agent modify governance artefacts it should only read?
Some of those checks can be deterministic. Some may need agentic review. Some should be warnings, not blockers. Some should be repo-configurable because different projects have different risk appetites, and because nothing says “enterprise adoption” like arguing whether a missing memory update is a soft fail, hard fail, or an angry comment from a bot with a tiny hat.
The point is not to automate judgement away.
The point is to move from “I hope the agent followed the principles” to “the PR has visible evidence that the principles were considered”.
That is the same pattern that turned tests from a developer habit into a CI control. Local discipline matters, but once the team depends on it, the discipline needs somewhere to run.
cARL personas: same runtime, different job
Once cARL starts becoming a review layer, another idea appears almost immediately: not every task needs the same cARL.
That does not mean separate governance universes. That way lies drift, sadness, and probably seven conflicting Markdown files called AGENTS.md. It means different personas or role profiles over the same canonical memory and instruction packs.
For example:
| Persona | Primary concern | Likely instruction emphasis |
|---|---|---|
| cARL Implementer | Bounded feature delivery | PR contract, language pack, tests, minimal diff |
| cARL Security Reviewer | Threat-aware review | security, identity, dependency, trust boundaries |
| cARL Pipeline Reviewer | CI/CD safety | platform/cicd, secrets, permissions, supply chain |
| cARL AppSec Analyst | Application security gaps | authn/authz, input validation, logging, dependency exposure |
| cARL Release Reviewer | Release safety | changelog, versioning, packaging, rollback, artefacts |
| cARL Documentation Editor | Durable knowledge quality | memory, invariants, docs consistency, user-facing accuracy |
This is where my earlier “cARL Does Weights” thought starts to make more sense. The same repository could have human-owned configuration that weights instruction packs differently for different roles. A security review would weight trust boundaries, identity, dependencies, and threat modelling more heavily. A documentation pass would weight accuracy, examples, and durable memory consistency. A release pass would weight packaging, distribution, provenance, and rollback.
The important bit is that the weights should be human-owned. Agents can read them. Agents can explain conflicts. Agents can propose changes. But the durable policy should not be casually rewritten by the same probabilistic worker it is supposed to constrain.
Because assumptions have teeth, and policy files are basically assumption kennels.
CopeLimit, cARRIE, and why governance needs a bill
The other half of this is telemetry.
CopeLimit started as a panic meter for GitHub Copilot AI Credits. That is not a formal product category, but it should be. “Panic meter” is probably more honest than half the observability market.
At first, CopeLimit existed to answer basic questions: how many credits have I used, how many remain, what happened at reset, when did overage start, and why does the official UI sometimes feel like it was assembled from vibes and eventual consistency?
But once AADLC and cARL entered the picture, the telemetry became more interesting. Credits were no longer just cost. They were behavioural evidence.
A sudden spike might mean a model performed repeated validation. Or got stuck in a correction loop. Or hydrated a repository from scratch. Or expanded a narrow task into architecture. Or generated a novella-length explanation of its own greatness before changing three lines of code. On some models, output tokens are expensive enough that verbosity is not just annoying. It is a line item.
That is where cARRIE fits.
Because of course there is another acronym. I apologise to nobody.
cARRIE stands for Cognitive Agent Runtime Resource Insights Engine.
The working relationship is:
- AADLC defines the lifecycle.
- cARL governs behaviour and stores durable repository truth.
- CopeLimit observes the raw AI credit/resource signals.
- cARRIE would interpret those signals as agentic FinOps evidence.
In other words:
cARL governs agent behaviour. cARRIE watches the bill.
The point is not just “spend less”. Spending less is nice, in the way that not setting fire to a sofa is nice, but it is not the full story. The real goal is to understand the relationship between task shape, model choice, context hydration, validation behaviour, correction loops, and cost.
If one model costs more because it found a real security issue, that is not waste. If one model costs more because it re-read the same repo structure four times and then apologised in paragraphs, that is waste wearing a cardigan.
The control loop needs both governance and telemetry. Otherwise we are just telling agents to behave and then refusing to look at the receipt.
Then Headroom enters, carrying a compression engine
Once cARL starts working, a second problem appears.
The agent is better governed, but the payload can still be enormous.
Durable memory helps stop rediscovery, but agents still ingest context, logs, tool output, search results, diffs, test failures, and whatever haunted scrollback the session has accumulated. Even governed cognition can be verbose. Sometimes especially governed cognition, because clear constraints have a way of becoming a lot of text.
This is where Headroom becomes interesting.
Headroom’s value proposition is token optimisation: compressing agent context and logs, reducing token payload, and helping agents learn from sessions. That is complementary to cARL. In fact, it is almost the missing optimisation layer in the stack.
But complementary does not mean harmless.
If cARL owns durable repository governance, Headroom must not accidentally mutate or compress away the governance truth. This matters because cARL projects canonical memory into generated harness files such as:
.github/copilot-instructions.md
CLAUDE.md
AGENTS.md
.cursorrules
ANTIGRAVITY.md
Those files are useful, but they are not necessarily the source of truth. In cARL’s model, they can be generated adapters. The canonical memory lives under .github/carl/.
If Headroom learns from a failed session and writes directly into CLAUDE.md or AGENTS.md, cARL may later overwrite that projection during a harness sync. The learned correction is lost. Worse, if multiple tools each assume they own the same instruction files, the repository gets duplicated context, conflicting guidance, and a delightful little context drift generator.
That is why I raised Headroom issue #1150: Path/glob-based ignore rules for compression, learning, and mutation.
The ask is not “please add special cARL support”. That would be the wrong abstraction. The ask is more general: allow repositories to declare paths that Headroom should not compress, learn from, or mutate directly.
Something like:
# .headroomignore
.github/carl/**
.github/copilot-instructions.md
CLAUDE.md
AGENTS.md
.cursorrules
ANTIGRAVITY.md
Or, more expressively:
[ignore]
compress = [
".github/carl/**"
]
learn = [
".github/copilot-instructions.md",
"CLAUDE.md",
"AGENTS.md",
".cursorrules",
"ANTIGRAVITY.md"
]
mutate = [
".github/carl/**",
".github/copilot-instructions.md",
"CLAUDE.md",
"AGENTS.md",
".cursorrules",
"ANTIGRAVITY.md"
]
That boundary is the architecture.
Headroom should reduce the cost of cognition. cARL should preserve the integrity of cognition.
Headroom observes, compresses, and learns around sessions. cARL stores approved durable truth and projects it back into harnesses. Learned corrections should ideally become structured suggestions that cARL can review or ingest, rather than silent edits to generated files.
That is the difference between an optimisation layer and a governance layer.
Mix them casually and you get drift. Separate them carefully and you get a closed loop.
Closed-loop AI governance
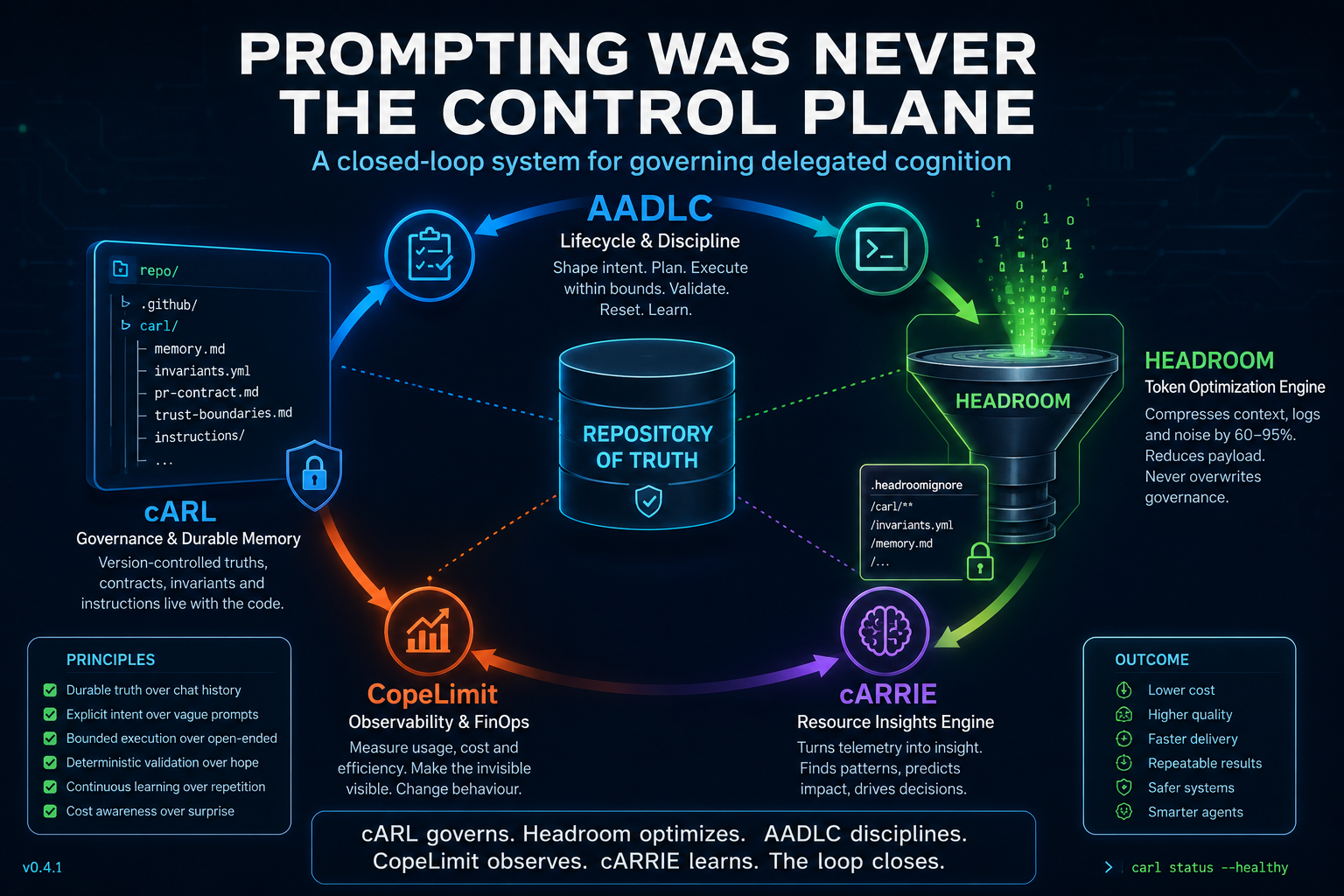
The architecture that is forming now looks something like this:
That is the loop:
- AADLC shapes the lifecycle.
- cARL stores and projects durable governance.
- Instruction packs tailor the agent’s behaviour to the task.
- The agent executes within a contract.
- Validation and review produce evidence.
- Durable memory is updated deliberately.
- CopeLimit and cARRIE observe resource behaviour.
- Headroom optimises context while respecting governance boundaries.
The important phrase is “deliberately”.
A system that learns by silently mutating whatever file it last touched is not a governance system. It is a haunted scrapbook. Closed-loop governance needs a feedback path, but it also needs authority boundaries. Otherwise every correction becomes another source of drift.
What has actually been proven?
“Proven” is a dangerous word, so let me be precise.
I have not proven that AADLC is universally optimal. I have not proven that cARL is the final form. I have not proven that Sonnet is always better for pragmatic implementation or that GPT is always better for architecture. I have not proven that Headroom plus cARL is safe, because the integration boundary is exactly the bit that still needs work.
What I do think the last few months have proven, in the practical engineering sense, is this:
First, agents repeatedly pay semantic hydration tax unless project truth is made durable. This shows up as repeated repo archaeology, repeated explanation, repeated validation setup, and repeated rediscovery of things the repository already knew yesterday.
Second, PR contracts reduce ambiguity. They do not make agents perfect, but they change the default from “infer what I meant” to “execute the approved scope”. That is a big shift.
Third, model choice is role choice. A model that is excellent for architecture may be expensive for narrow implementation. A model that is excellent for pragmatic delivery may under-explore broader design implications. The solution is not one favourite model. The solution is to route work by role, risk, and ambiguity.
Fourth, planning can reduce executor cost when ambiguity would otherwise cause expansion. The Sonnet-planner/GPT-executor benchmark demonstrated that very cleanly. Planning was not free, but it reduced GPT’s ambiguity-driven architecture spread.
Fifth, cARL-style principles are useful beyond implementation. They can structure PR review, security pipeline analysis, and application security gap review, even before a target repository has cARL installed.
Sixth, optimisation layers need governance boundaries. A tool that compresses context or learns from sessions can be extremely valuable, but it must not silently overwrite the source of truth.
Seventh, AI FinOps is not just spend management. It is behavioural telemetry for delegated cognition. Costs are signals. Annoying signals sometimes, but signals.
That is enough evidence for me to stop treating this as a private workflow and start treating it as an architecture.
The future shape
The direction from here is fairly clear, which is always suspicious.
cARL needs to keep becoming more portable and less dependent on me remembering which instruction pack I invented at 1am. The CLI already makes installation and repair possible. The next level is richer diagnostics: does the repo have the expected artefacts, are generated harness projections in sync, does the current PR contract exist, are trust-boundary changes recorded, and has memory drifted from implementation reality?
cARLy Gates is the natural CI extension of that. I want a PR check that can say, with evidence, whether a change appears to respect the repository’s cARL contract. Some checks can be deterministic. Some can be assisted. The point is not to let an agent become judge, jury, and merge button. The point is to turn invisible governance assumptions into visible review artefacts.
Personas are the natural operational extension. A cARL Security Reviewer should not behave like a cARL Documentation Editor. A cARL Pipeline Reviewer should care about different blast radii than a cARL Implementer. Same memory, same canonical truth, different weighted lenses.
cARRIE is the natural FinOps extension. CopeLimit tells me what happened to the credits. cARRIE should eventually help explain why it happened and what delegation pattern caused it.
Headroom is the natural optimisation extension, provided the boundary is safe. Compress logs. Reduce repeated context. Learn from failed sessions. Brilliant. But do not mutate .github/carl/**. Do not treat generated harness files as canonical memory. Export learned corrections as suggestions. Let the governance layer decide what becomes durable truth.
That is the whole architecture in one mildly overdramatic paragraph:
AADLC defines the loop. cARL stores the truth. Instruction packs shape the role. cARLy Gates bring the contract into CI. CopeLimit measures the resource signal. cARRIE interprets the bill. Headroom compresses the cognitive payload. Humans retain authority over durable policy.
Not a bad accidental architecture, honestly.
Annoying that it started with a billing change.
Closing thoughts
When I wrote the first AADLC post, I thought I was describing a better way to work with coding agents.
I still was. But I was also circling a bigger thing without quite naming it.
AI coding agents are not just autocomplete with ambition. They are delegated cognition systems operating over code, tests, tools, repository state, CI, secrets, dependencies, deployment paths, and hidden execution graphs. Treating them as chatbots is comforting, but wrong. Treating them as junior developers is sometimes useful, but still incomplete. Treating them as autonomous workers operating inside a constrained engineering control system gets much closer.
That is why prompting was never the control plane.
The control plane is the combination of durable memory, explicit scope, trust boundaries, validation, telemetry, review, and governed learning.
AADLC gave me the loop.
cARL gave it a repository-native body.
The benchmarks gave me evidence that delegation shape changes behaviour and cost.
The review use cases showed that cARL principles can guide more than feature implementation.
cARLy Gates points toward CI.
cARRIE points toward FinOps interpretation.
Headroom points toward context optimisation, provided the governance boundary holds.
None of this makes agents perfect. That was never the point. Perfect systems are usually either fictional, under-tested, or waiting for the first customer.
The point is to make failure modes diagnosable, bounded, recoverable, and eventually learnable.
The point is to stop making agents rediscover gravity every session.
And, ideally, to stop paying them to do it .