At some point very early this morning, because apparently this is what my life is now, I found myself watching a tiny dashboard called CopeLimit while GitHub Copilot’s new AI Credits billing model went live.
This was not the original plan for the morning.
The original plan was probably something normal, like sleeping, or at least pretending to be the sort of person who sleeps. Instead I was refreshing a usage meter, running GitHub coding-agent sessions, looking at Netlify logs, requesting CSV billing reports, checking iOS widgets, and watching the old “Premium requests” world become the new “AI credits” world in real time.
In other words, completely normal behaviour for someone who looked at usage-based AI billing and thought:
This needs a panic meter.
Welcome to the first morning of the AI Credits era. Same goblin. Different unit.
The visible model changed first
The most obvious change is the language.
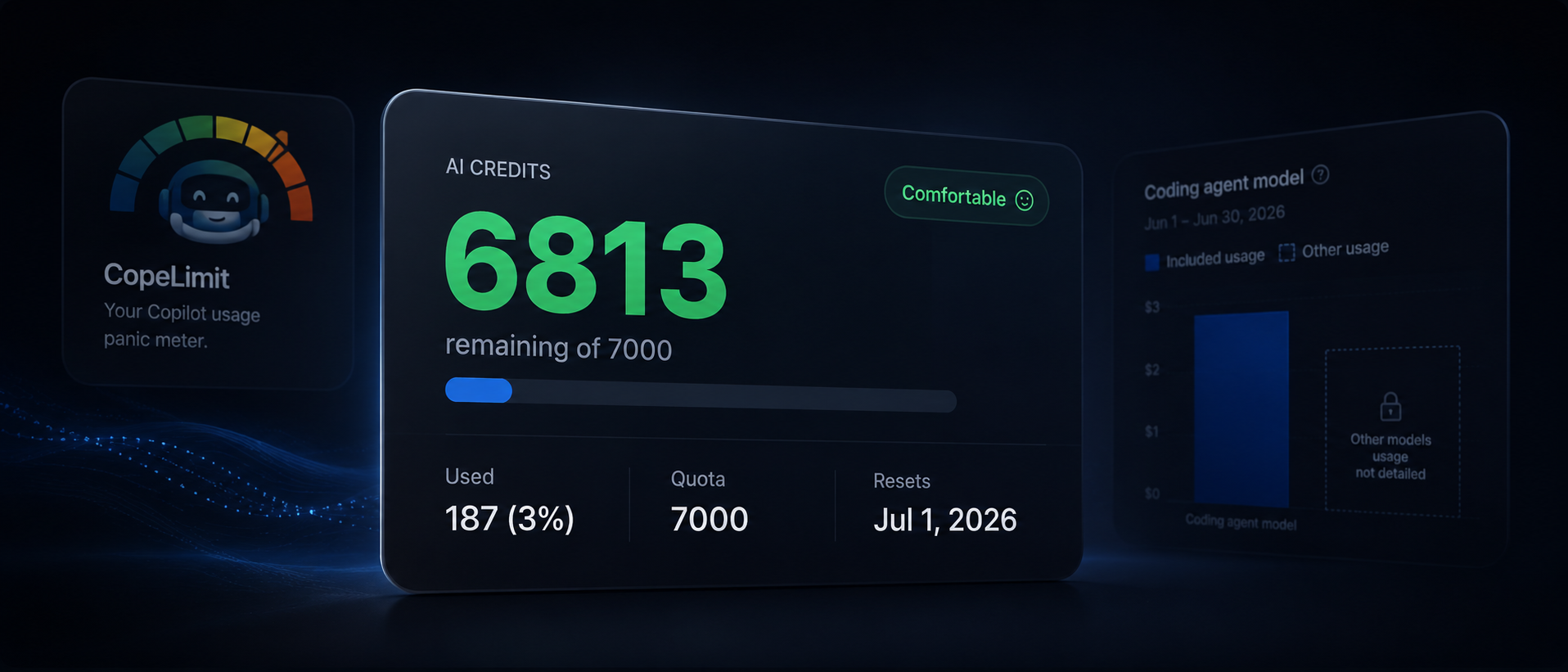
GitHub’s billing UI now shows Included credits and AI credits rather than Premium Requests. For my Copilot Pro+ account, the allowance is now shown as:
7,000 AI credits
Additional usage is separately shown as disabled, with a $0 / $0 budget. That matters. It means the included allowance can be consumed, but pay-as-you-go spend should not happen unless additional usage is explicitly enabled.
That is a good safety rail. It is also the sort of thing I want exposed very clearly because “surprise AI bill” is not a vibe I am interested in beta-testing before breakfast.
The initial visible state was reassuring enough:
Included credits: 0 / 7,000 AI credits
Additional usage: not enabled
Reset: 1 July 2026
So far, so sane.
Then I looked under the floorboards.
The API still smells like the old world
The live internal Copilot API response did not suddenly become a clean new AI Credits object. CopeLimit was still able to read the same legacy-shaped quota fields it had been reading before:
{
"quota_snapshots": {
"premium_interactions": {
"remaining": 7000,
"entitlement": 7000
}
},
"quota_reset_date_utc": "2026-07-01T00:00:00.000Z",
"token_based_billing": "..."
}
The important bit is not that the old premium_interactions structure still exists. Backwards-compatible migration shapes are normal. The important bit is that the values now appear to represent AI Credit units, even though the object name still says premium_interactions.
That is very migration-shaped. The customer-facing UI has moved on. The backend compatibility furniture is still in the hallway.
CopeLimit originally normalised this payload as:
{
"mode": "premium_requests",
"quota": 7000,
"remaining": 7000
}
That was technically useful but semantically wrong once the new billing model was live. The app could still show the right numbers, but it was calling them by the old name, which is exactly the kind of small lie that metastasises into operational confusion later.
The fix was simple: detect the billing marker and change the normalised mode.
body.token_based_billing === true ||
body.quota_snapshots?.premium_interactions?.token_based_billing === true
Only explicit boolean true counts. Not field presence. Not "true". Not 1. Not whatever future weirdness appears after a frontend engineer and a billing system have a spirited disagreement at midnight UTC.
Once that landed, CopeLimit correctly displayed:
AI credits
6769 remaining of 7000
231 used
The old fields still provided the data. The new marker provided the meaning.
That is the kind of compatibility layer I can live with.
The official report confirmed the economics, then disappointed me spiritually
GitHub’s AI usage report arrived quickly. That part worked.
The report confirmed the key economics:
product,sku,model,quantity,unit_type,applied_cost_per_quantity,gross_amount,discount_amount,net_amount,total_monthly_quota
copilot,coding_agent_ai_credit,Coding Agent model,230.20809,ai-credits,0.01,2.3020809,2.3020809,0,7000
So, confirmed:
1 AI Credit = $0.01
230.20809 AI credits = $2.3020809 gross usage
included-plan discount = $2.3020809
net amount = $0
monthly quota = 7000 AI credits
That is useful. It also aligns with the GitHub billing page, which showed 230 / 7,000 AI credits, and with CopeLimit, which showed 231 used based on the integer live remaining value.
There is a tiny rounding difference here, and it is worth noticing. GitHub’s billing report has decimal precision. GitHub’s billing UI appears to floor the display value. CopeLimit’s live meter uses the integer remaining value from the internal API:
GitHub report: 230.20809 AI credits
GitHub billing UI: 230 AI credits
CopeLimit live API: 231 used, because 7000 - 6769 = 231
None of those are necessarily wrong. They are different resolutions of the same underlying usage. This is why FinOps tools need to understand source semantics rather than pretending every number with the same label is the same measurement.
Then there is the bad bit.
The report only says:
model: Coding Agent model
Come on, GitHub.
That tells me I used AI Credits on the coding agent. It does not tell me whether the burn came from Claude Sonnet 4.6, GPT-5.3-Codex, Auto-routing, or a tiny invisible committee of models wearing a trench coat. It does not tell me which repo, branch, PR, session, task type, phase, or validation loop caused the usage. It is a billing report, not an engineering observability report.
Which is fine, as far as it goes.
It just does not go very far.
The model dropdown lost the useful fear labels
Before this change, Premium Request multipliers at least provided a visible hint that some model choices were more expensive than others. It was crude, but it worked as a warning label.
After the change, the model picker groups models by capability language:
Fast and cost-efficient
Versatile and highly intelligent
Most powerful at complex tasks
That is friendlier. It is also less useful.
Under AI Credits, cost is no longer a neat “one request equals one unit” mental model. The cost depends on token volume, context size, cache behaviour, tool loops, file reads, output length, validation retries, and whatever model-specific pricing or routing GitHub applies beneath the UI.
Removing the visible multiplier means the user gets a capability hint, but not a price signal.
That matters because engineers will optimise what they can see. If the UI hides model-specific cost behaviour, people will either ignore the cost until Finance notices, or they will build their own little field instruments.
Naturally, I built the little field instrument.
CopeLimit survived the migration, but that is not enough
CopeLimit started as a joke with a useful number attached. It was a “Copilot usage panic meter”: how many Premium Requests do I have left, when do they reset, and should I stop summoning the agentic beast before the month ends?
It is still that, except now the unit is AI Credits and the joke has acquired accounting implications.
The live API is enough for CopeLimit Core:
quota
remaining
used
reset date
billing mode
source
warning level
That is enough for a panic meter. It is enough for a widget. It is enough to show whether usage is moving in real time. It is enough to prove that GitHub’s backend compatibility fields still carry usable information.
It is not enough for FinOps attribution.
CopeLimit cannot infer which agent session burned credits. It cannot know which model was selected. It cannot know whether Auto routed elsewhere. It cannot know whether a cost delta came from semantic hydration, implementation, validation, review-hardening, retries, or me poking the system because reality had become interesting.
For that, CopeLimit would need a second layer.
Not just a meter.
A ledger.
Billing is not observability
This is the big observation from the first morning.
GitHub now gives me a bill. It does not give me a flight data recorder.
A bill says:
Coding Agent model: 230.20809 AI credits
An engineering observability system would say:
Repo: goldjg/CopeLimit
Branch: copilot/cope-limit-github-billing-transition
Model selected: Claude Sonnet 4.6
Task: AI Credits billing-mode detection
Phase 1: implementation + tests
Phase 2: review-hardening
Start meter: 77
End meter: 231
Observed delta: 154 AI credits
Files changed: 6
Tests: 50/50 pass
Build: pass
Lint: known unrelated TS5107
Outcome: mergeable
Those are very different things.
The first is useful for billing reconciliation. The second is useful for engineering governance.
That distinction is going to matter a lot more now.
AADLC finally has numbers attached
The timing here was useful because I had already been working on AADLCv2: a way of splitting agentic development into shaped, planned, bounded, validated, resettable work. The theory was that durable context, explicit PR contracts, memory, invariants, and scoped prompts should reduce repeated semantic rediscovery and make agent work more governable.
The new billing model gives that theory a cost surface.
The first observed CopeLimit datapoints were rough but interesting:
Semantic hydration baseline:
~77 AI credits
broad durable-state setup
no source code changes
Targeted implementation + tests + review hardening:
~154 AI credits
billing-mode detection
code + tests + memory update
Planning-only diagnostics:
~39 AI credits
provider-capture 403 investigation
no files changed
That does not prove AADLCv2 makes agentic development cheaper. Not yet.
It does prove something more immediately useful: the cost is decomposable. I can see the difference between hydration, implementation, review-hardening, and planning. I can compare runs. I can start spotting whether a session is spending credits on actual work or repeatedly rediscovering what the repository is for.
That is the beginning of FinOps for delegated cognition.
Not a slogan. A measurement problem.
The report picker lied about May, because of course it did
One of the funnier observations was the GitHub report modal.
The usage page clearly showed the June billing period:
Jun 1 – Jul 1, 2026
The report picker, however, offered:
Today: May 31, 2026
Current month: May 2026
Last month: May 2026
Two Mays enter. No Junes leave.
I requested “current month” anyway, because if a billing UI offers me Schrödinger’s May, I am going to open the box.
The report email arrived with:
Usage report for June 01, 2026
So the report backend was right. The picker labels were wrong.
That is not catastrophic. It is also not great. Billing UIs are trust surfaces. If the page, modal, and report disagree about what month it is, users will not calmly conclude “ah yes, probably a harmless frontend date helper.” They will conclude, correctly, that cost reporting needs independent verification.
Again: this is why observability matters.
The capture system immediately became important
CopeLimit had provider capture support intended to persist sanitised snapshots of raw provider responses. That is useful when APIs change, because it lets you compare what the provider returned before and after a migration.
Naturally, on the morning this became most useful, Netlify Blobs started returning 403s on the capture persistence path.
The user-facing usage response still worked. Capture was fire-and-forget, as it should be. But the logs showed:
[capture-store] Failed to persist provider capture
provider: github-copilot-internal
error: Netlify Blobs has generated an internal error (403 status code)
stack: ... readIndex ... persistCapture ... maybeCapture
That is another important lesson. Once AI billing becomes something you want to observe, your observability pipeline becomes part of the product. If the live meter works but the capture recorder is broken, you can still fly, but you lose the black box.
The next CopeLimit work item is therefore not a shiny chart. It is boring resilience: classify Blob failures, log safe structured diagnostics, suppress repeated noisy failures, and preserve the invariant that usage responses must never fail because capture failed.
Compounding boring. Again.
The real product split: panic meter vs FinOps ledger
The more I watched the new billing model, the clearer the product boundary became.
CopeLimit Core is the panic meter:
How many credits are left?
How many have I used?
When does the quota reset?
Is the live source working?
Is the billing mode AI Credits or legacy Premium Requests?
CopeLimit FinOps would be something else:
Import GitHub AI usage CSV reports
Poll live API checkpoints
Ingest AADLC run summaries
Correlate PRs, branches, models, tasks, phases, and credit deltas
Show confidence levels for attribution
Separate reported decimal credits from live integer balance deltas
Flag unattributed usage
Highlight expensive phases
Compare model/task classes over time
That second layer cannot come from the GitHub live quota API alone. It needs reconciliation.
GitHub gives the bill. AADLC gives the story. CopeLimit FinOps would reconcile the two and tell me whether the story matches the bill.
That is the missing layer.
What I trust so far
After the first morning, these are the observations I trust.
GitHub AI Credits are live. The UI, report, and live API all support that conclusion.
The compatibility shape still matters. quota_snapshots.premium_interactions remains a useful source of quota and remaining values, even though the customer-facing unit is now AI Credits.
The token_based_billing marker is the semantic switch. Treating the old object name as the billing mode would be wrong.
The GitHub UI floors headline credit usage. The report has decimal precision. The live API exposes integer remaining/quota values. These are related but not identical views.
The GitHub report is billing-useful but engineering-poor. “Coding Agent model” is not enough attribution for agentic FinOps.
The model picker no longer gives visible multiplier-style cost hints. That pushes empirical measurement onto users who care.
AADLC cost measurement is now possible, but only if run boundaries are recorded. Without run summaries, live meter deltas become ambiguous quickly.
CopeLimit is useful as a meter today. It needs CSV ingestion and AADLC summary ingestion to become a FinOps tool.
What I do not trust yet
I do not yet trust that the internal API shape is stable. It is an internal API. The clue is in the name, and the teeth are in the word “internal”.
I do not trust the report modal labels after watching it insist that both current month and last month were May 2026.
I do not trust model cost attribution because GitHub is not exposing model-level billing detail in the report I received.
I do not trust the capture pipeline until the Netlify Blobs 403 is diagnosed and capture persistence is working again.
I do not trust any claim that AADLCv2 reduces cost until there are more runs, better attribution, and enough comparable PRs to make the conclusion less vibes-shaped.
That last point matters. I have early evidence. I do not have proof.
That is fine. Engineering starts with observations before it earns graphs.
So what changed?
The billing unit changed, obviously. Premium Requests are no longer the visible mental model. AI Credits are.
But the deeper change is that the cost surface moved closer to the actual work. The old model encouraged people to think in visible interactions. The new model forces us to think in hidden execution: context, tools, repo traversal, tests, validation, retries, model choice, and workflow shape.
That is healthier in one sense. It prices the thing that is actually being consumed.
It is also more dangerous, because hidden work is harder to govern. If the platform does not expose enough attribution, users will either fly blind or build their own instruments.
I appear to be building instruments.
Again.
Final thought
The first morning of AI Credits did not feel like a disaster. It felt like a migration.
The numbers worked. The old fields still carried usable data. The new UI exposed the allowance. Additional usage was safely disabled. The report reconciled with the live meter closely enough to trust the broad accounting.
But it also exposed the next problem.
Billing has arrived before observability.
That is not unusual. Cloud did this too. First came the bill. Then came the dashboards, tags, budgets, chargeback, showback, anomaly detection, rightsizing, and all the other machinery we built after discovering that “it scales” also meant “it invoices”.
AI agents are now entering the same phase.
The bill says I used 230.20809 AI Credits.
The engineering question is:
Doing what?
Until the platform answers that properly, CopeLimit will keep watching the meter, AADLC will keep writing the story, and somewhere between the two there is a FinOps ledger waiting to be built.
Because apparently cognition is infrastructure now.
And infrastructure needs observability.